When you opt to store the binary files on local network storage, there are a few items to keep in mind:
- When Octopus is hosted on Windows it can be a mapped network drive e.g.
X:\or a UNC path to a file share e.g.\\server\share. - When Octopus is hosted as a container it must be as a volume.
- The service account that Octopus runs needs full control over the directory.
- Drives are mapped per-user, so you should map the drive using the same service account that Octopus is running under.
Most commercial network storage solutions will work perfectly well with Octopus Deploy. They will use industry-standard mechanisms for data integrity, for example, RAID or ZFS, and have the capability to perform regular backups.
High Availability
With Octopus Deploy’s High Availability functionality, you connect multiple nodes to the same database and file storage. Octopus Server makes specific assumptions about the performance and consistency of the file system when accessing log files, performing log retention, storing deployment packages and other deployment artifacts, exported events, and temporary storage when communicating with Tentacles.
What that means is:
- Octopus Deploy is sensitive to network latency. It expects the file system to be hosted in the same data center as the virtual machines or container hosts running the Octopus Deploy Service.
- It is extremely rare for two or more nodes to write to the same file at the same time.
- It is common for two or more nodes to read the same file at the same time.
In our experience, you will have the best experience when all the nodes and the file system are located in the same data center. Modern network storage devices and operating systems handle almost all the scenarios a highly available instance of Octopus Deploy will encounter.
Disaster Recovery
For disaster recovery scenarios, we recommend leveraging a hot/cold configuration. The file system should asynchronously copy files to a secondary data center. When a disaster occurs, create the nodes in the secondary data center and configure them to use that secondary file storage location.
There are many robust syncing solutions, but even simple tools like rsync or robocopy will work. As long as they periodically run, that is all that matters.
One common approach we’ve seen is leveraging a distributed file system (DFS) such as Microsoft DFS. DFS will work with Octopus Deploy, but it must be configured in a specific way. Unless you configure it properly you’ll encounter a split-brain scenario.
DFS
DFS in the standard configuration (i.e., accessed through a DFS Namespace Root) is not suitable for use as a shared file store with Octopus Deploy.
Operating Octopus Deploy with the non-recommended DFS configuration will likely result in intermittent and potentially significant issues.
Below are recommendations and more details on:
Configuring DFS with a Single Octopus Server
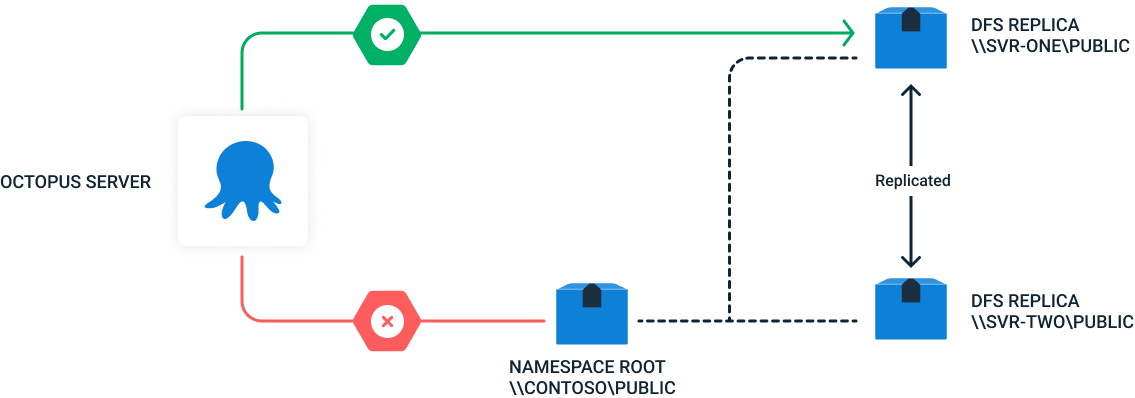
For a single-node Octopus Server using DFS for file storage, the node must be configured to use a specific DFS Replica and not the DFS Namespace Root. Despite no contention between nodes in the single-node configuration, there is still the DFS location transparency, which will cause unpredictable behavior when the node is directed to a different replica.
In the diagram, the single node is configured to use the replica \\SVR_ONE\public as the DFS file share and not the namespace root (\\Contoso\public).
Configuring DFS with a Multi-Node Octopus Server cluster (Octopus HA)
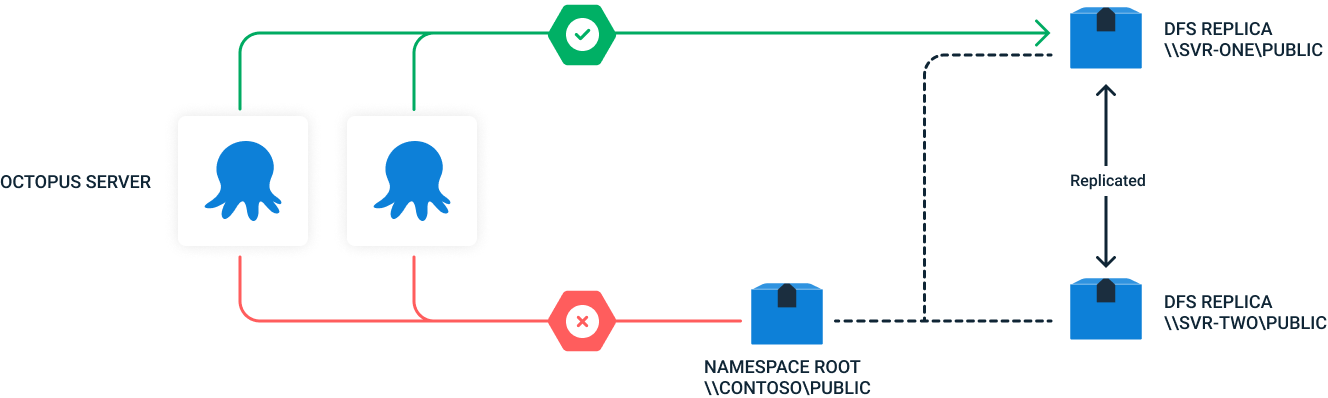
For a multi-node Octopus cluster using DFS for file storage, it is imperative that all nodes in the cluster are configured to use the same DFS Replica and not the DFS Namespace Root. Both using the namespace root or using different replicas for different Octopus nodes will cause unpredictable behavior.
In the diagram below each node in the cluster is configured to use the same replica (\\SVR_ONE\public) as the DFS file share and not the namespace root (\\Contoso\public).
DFS for Redundancy (Disaster Recovery)
DFS can still be used for redundancy and disaster recovery, as usual.
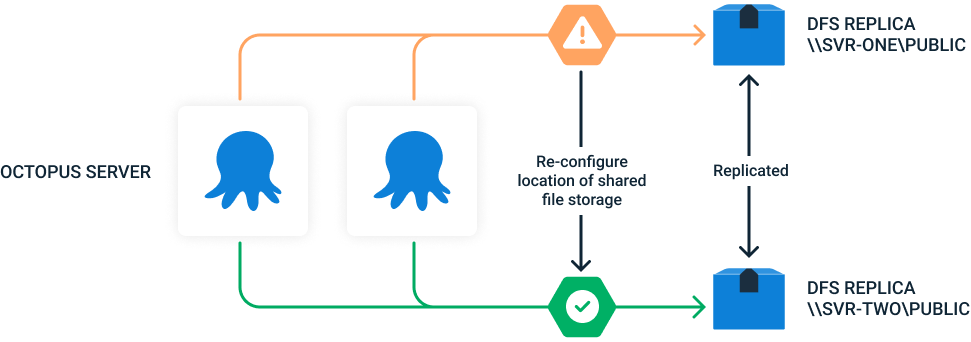
If the replica that Octopus is configured to use becomes unavailable, simply changing the configuration to another replica in the DFS Namespace with the same target folders is sufficient to restore service.
Octopus does not need to be restarted in this scenario. Customers can either do this manually or can automate it.
In the simplified diagram below, when an outage at DFS Replica \\SVR_ONE\Public occurs, by re-configuring each Octopus node to use a different replica (ensuring all nodes are re-configured to the same replica), customers can still take advantage of the redundancy within DFS.
Help us continuously improve
Please let us know if you have any feedback about this page.
Page updated on Wednesday, May 22, 2024