Workers were introduced in Octopus Server 2018.7 as a way to offload work done by the Octopus Server. Worker pools are groups of workers. You configure your deployment or runbook to run on worker pools.
Workers serve as “jump boxes” between the server and targets. They are used when the Tentacle agent cannot be installed directly on the target, such as databases, Azure Web Apps, or K8s clusters. Workers are needed because the scripts to update the database schema or the kubectl scripts to change the K8s cluster have to run somewhere.
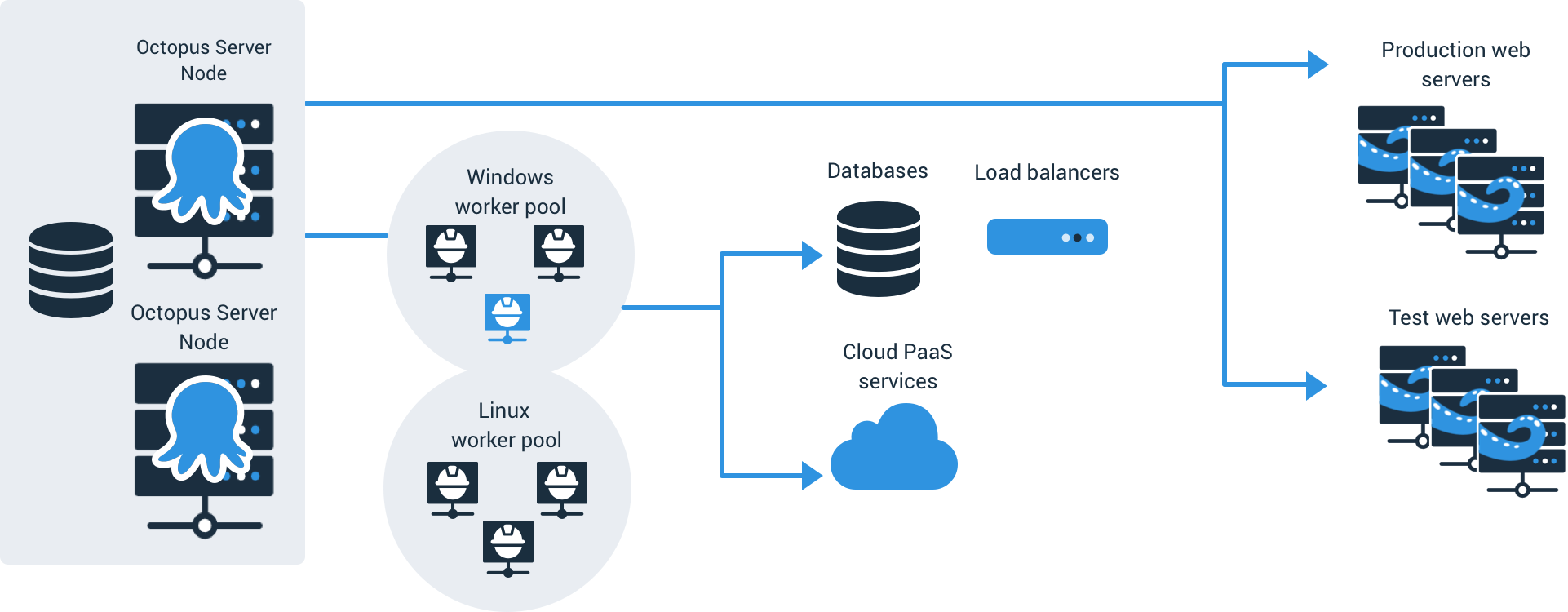
When you do a deployment or a runbook run with workers, a worker is leased from the pool; the work is done, then the worker is added back into the pool. The vast majority of the time, the same worker is used for a single runbook run or deployment. But the worker can change in the middle of the deployment; you should design your process around that assumption.
The leasing algorithm is not round-robin. It looks for the worker with the least amount of active leases. Multiple concurrent deployments or runbook runs can run on a worker.
Some important items to note about workers:
- Unlike deployment targets, workers are designed to run multiple tasks concurrently.
- Octopus Server 2020.1 added the Worker Pool Variable Type making it possible to scope worker pools to environments.
- Octopus Server 2020.2 added the execution container for workers feature, making it easier to manage software dependencies.
- We provide a Tentacle docker image that can be configured to run as a worker.
Provided Workers
The Octopus Server includes a built-in worker. When you configure a deployment or runbook to run tasks on the server, it is handing off that work to the built-in worker.
Octopus Cloud is running the Octopus Linux container. To ensure maximum cross-compatibility with both Windows and Linux, the built-in worker is disabled on Octopus Cloud. Instead, we provide you with the ability to choose from 2 dynamic workers, Windows Server 2019 and Ubuntu 22.04. Each worker type is a different worker pool.
The built-in worker and dynamic workers were created to help get you started. Using them at scale will quickly expose their flaws.
- The built-in worker will run under the same account as the Octopus Deploy service. By default, that is
Local System. You can change it to run under a different account, but it can only run under one account. You cannot change that account during a deployment or runbook run. - The built-in worker may or may not be in the same data center as your deployment targets. You could experience some significant latency.
- Dynamic workers and built-in workers are limited to the software installed on the host servers. This includes specific software. Upgrading to a newer version results in a “big bang” change in your CI/CD pipeline which increases risk.
- The IP address assigned to dynamic workers will change at most once an hour and at least once every 72 hours.
- Dynamic workers are assigned to an entire instance, not just a space. We have seen cases where a deployment blocks on one space, blocking a deployment on another space because they both used the same dynamic worker.
- There is only one dynamic worker per pool. Workers have some blocking tasks (install Calamari and downloading a package). If a process needs to acquire a mutex for that blocking task, it has to wait until other tasks are done.
Workers for Octopus at scale
If you plan on using Octopus Deploy at scale, disable the built-in worker for self-hosted or stop using the dynamic workers and host your own workers and worker pools.
- Establish an easy-to-understand naming convention for workers. For example,
p-db-omaha-worker-01for a worker located in Omaha to do database deployments on Production. - Configure workers to run in the same data centers as your deployment targets. For example, if you are hosting Octopus Deploy in an on-premise data center, but you are deploying to the US-central region in Azure, then create workers to run in that region in Azure.
- Name the worker pool to match the purpose, location, and environment. For example,
Azure Central US Production Worker Pool. - When possible, configure the underlying Tentacle Windows service as a specific Active Directory account to better control the permissions. Consider not only what it should have access to (this worker can run SQL Scripts on a Dev SQL Server) and what it shouldn’t have access to (this worker cannot run SQL Scripts on any Test or Production SQL Server).
- For redundancy, have at least two workers per pool.
- Whenever possible, leverage execution container for workers to limit the amount of software to install and maintain on the workers.
Compute resources required
Workers don’t need a lot of compute resources. Our recommendations are:
- 1 CPU / 2 GB of RAM for Linux workers (both server and container)
- 2 CPU / 2 GB of RAM for Windows workers
Naturally, the more compute resources you add, the faster the worker will run. Monitor the resources of each worker and increase when needed. Or add more workers to spread out the load.
The difference between workers and high availability nodes
With workers’ introduction, there was some confusion as to the difference between a worker and a high availability node. They are not the same thing. Here are the key differences.
- A high availability node runs the Octopus Server service while a worker is running the Octopus Tentacle service.
- A high availability node is responsible for hosting the Octopus Deploy UI while a worker does no such thing.
- A high availability node orchestrates and coordinates deployments and runbook runs, while a worker may be used to run 1 to N steps in a deployment or runbook run.
Think of the high availability node as the manager and the worker as the worker doing the work.
The difference between workers and deployment targets
Behind the scenes, there isn’t much difference between a deployment target or a worker, as both are Tentacle agents. It is a matter of how they are registered. Deployment targets are registered to environments while workers are registered to worker pools. It is how the server hosting the Tentacle will be used. Deployment targets are for deploying to (web server, application server, etc.) while workers are used as a means to deploy to a deployment target.
A listening Tentacle can be registered as both a worker and a deployment target. We don’t recommend it, but it is possible.
All Octopus Cloud and self-hosted Server, Data Center, and Standard licenses offer unlimited workers.
Further reading
For further reading on workers in Octopus Deploy please see:
Help us continuously improve
Please let us know if you have any feedback about this page.
Page updated on Wednesday, October 4, 2023